引子
第一章其实是个简介、大纲性质的章节,主要是介绍可靠性、可扩展性、可维护性的概念,这也是我们设计和维护系统的时候总是会面对的概念,它们穿插在整本书中。本章在介绍这些概念的时候很多地方也是以列举一条条更细的概念来展开的。如果完全按照他的内容来来写就会变成照搬,所以我会加一点扩展和我在实际工作中遇到的情况。
认识数据系统
数据系统的分类
从负载类型来区分的话,数据系统可以分为两种典型的负载类型,数据密集型和计算密集型。
其中数据密集型以大数据相关技术为代表,最有名的就是Hadoop生态的各种组件,如用于数据存储的 HDFS
、HBASE,用于数据批处理的 MapReduce 和 Spark,用于流式处理的 Storm、Spark Streaming。从这些组件的功能就可以看出,数据密集型主要关注的是用分布式系统来存储和处理数据。
计算密集型以目前非常火的深度学习为代表,因为深度学习模型中的网状模型的训练需要大量的输入和待学习参数,学习过程中每一次正向传播和反向传播更新的参数量可能是百万、千万甚至亿级别的,需要大量的计算量,这些计算大多是矩阵计算,所以 GPU 比 CPU 更擅长这种运算。
当然这种分类只是从负载类型来看,在实际应用中这两者其实没有那么明显的界限。深度学习可以看成是大数据的上层应用,依赖数据处理系统进行数据存储、数据清洗、特征工程等。他们都属于数据系统,但是本书主要关注的是前者,也就是数据密集型系统设计。
数据系统的组成
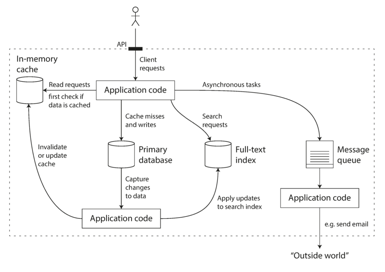
这是书中给出的一张数据系统的架构图,其实如果做过 web 服务的可能会对它感到亲切,就是一个简单的网站的后端架构图,或者说更通用一点,是基于 request 和 response 提供服务的这样一个应用。
客户端调用到达之后,如果是读请求,则先访问内存中的缓存数据,如果缓存中没有命中则需要击穿到“主数据库”中取数,然后再通过应用代码把数据更新到缓存中;如果是写数据,则先写“主数据库”,然后再把数据更新到缓存中。这也是网站最基本的处理流程和相关组件。
如果有搜索请求,则应用代码会到全文索引数据库中查找,比如我们熟悉的 ElasticSearch。
对于不需要马上响应或者马上执行的任务(比如图中发邮件的例子),可以先把请求放到消息队列中,然后由其他的线程或者进程从队列中把消息拿出来然后异步地处理掉。
在这张架构图中涉及到的数据组件有,数据库(database)、缓存(cache) 、流式处理(stream processing)、批处理(batch processing)。这些组件在有一定数据量的服务中还是比较常见的。并且在图中每个组件都是以单点的形式在图中展现的,在实际应用中往往会更加复杂,图中的每个组件节点都可能是一个集群。还有一些属于数据密集型应用的组件并没有在图中得到展现,比如围绕hadooop生态链的批处理工具。
整本书也是围绕着这些组件的发展、应用、原理以及组件与组件之间的交互来展开的。
可靠性
对软件的期望
软件作为工具,我们就会对这些工具有着特定的期望。典型的期望如下:
- 应用程序表现出用户所期望的功能
这是对软件作为工具最基本的要求,是锤子至少得能敲东西,是钉子至少得能钉东西是吧。 - 允许用户犯错,允许用户以出乎意料的方式使用软件
所谓出乎意料的方式,就是指没有在PRD、设计文档、用户使用手册上出现的操作。当用户出现这些操作的时候,至少要保证服务不能崩吧,如果能有错误提示信息甚至在用户出错之后能够引导用户进行正确操作就更好了。 最简单的例子就是参数校验,不让错误的请求流向应用更深层次的地方;还举个例子就是使用预编译的SQL语句,防止注入攻击等,在Java中通常框架已经帮我们做了。 - 在预期的负载和数据量下,性能满足要求
在电商网站中,如“双十一”、“双十二”这种大促的时候,网站流量会成倍地增加。而高并发的请求往往是网站性能的大杀器。这就要求我们在设计网站的时候就要考虑这种问题,也就是设计负载要远远大于平时的实际负载,并且在大流量到来之前通过压测、模拟和软硬件的扩容来合理应对。 - 系统能防止未经授权的访问和滥用
这就要靠系统的认证(Authentication)授权(Authorization)模块了。这两者的区别可以简单类比为,认证就是“证明你是你”;授权则是告诉你可以访问哪些模块。
当软件对这些期望满足得越多,则说明该软件越“可靠”。
硬件可靠性
硬盘崩溃、内存出错、机房断电、拔错网线……这些都是属于硬件可靠性的范畴。通常的做法就是提供“冗余”。磁盘阵列(RAID)、热插拔内存、备用电源或者发电机等都这这种“冗余”的具体体现。
软件可靠性
在对软件的期望小节中,我们谈到软件可靠性的表现形式。而在上面的数据应用架构图中,数据可能流经的每一个分支、每一个组件都会面临可靠性的挑战,尤其是在负载变高的情况下。那么要怎么实现可靠性呢。
对于 Application Code 来说保证可靠性的方式就是避免单点。避免单点的方式又分为横向扩展和纵向拆分。所谓横向扩展,就是把同一套代码部署在多个服务器中,然后用负载均衡把客户端的请求分散到各个服务中,降低单个服务的压力。纵向拆分就是把同一个请求路径上的不同软件模块部署到不同的服务器中,然后服务与服务之间的请求在用HTTP或者rpc串联起来。比如在Java中,就可以把经典的三层结构Controller、Service、和DAO层作为独立的服务部署,这也正是微服务的思想。
对于数据库来说,想要提高性能常用的方式包括:优化SQL、增加索引、分库分表、读写分离。在高并发场景中,数据库的选型已经数据模型的选项变得至关重要。在跟我们公司的DBA沟通的时候,对于不同的请求量(QPS),他给出一些比较有参考价值的选型建议:
QPS 1-9k,直接用mysql就能搞定;
10k以上的写入QPS,mysql就需要考虑分库分表;
几十k的情况下,也可以考虑TiDB这种NewSql,我们之前在实际工作中压测过 TIDB,水平大概就处于这样一个水平;
100k以上, mysql 分库分表资源消耗很大,性价比变低,TiDB 同样已经比较吃力,可以考虑使用考虑 kv 存储这种 Nosql。
Kv存储的话,也有两条路线,一条就是有钱就上 redis,因为是内存,比较贵,DBA那边的观点是几十几百个G还能忍,太多就不行,太伤钱了得评估性价比;另外一条就是用 pika 或者 MongoDB 这种分布式 kv 存储,然后再用 SSD 进行支撑。
除了QPS,也可以根据响应时间(P99)作数据库选型:
如果使用TiDB,必须将预期响应时间定为100毫秒以上
对mysql进行小心设计和表结构优化,P99预期可以做到10毫秒以内
需要毫秒级别的响应只能上 redis 这种内存数据库
这里我们较为详细讨论的应用层代码和数据库,但是事实上,图中画出的每一个组件,以及在软件构建过程中引入到系统中的每一个组件,都需要考虑可靠性问题。只有这样我们才能说,整个系统是可靠的。
可扩展性
可扩展性意味着,如果系统以某种方式增长,我们应对增长的措施有哪些。
书中举了 twitter 用户发布推文的例子,还是挺有代表性的。我们可以把它想象成微博,可以进一步想到每次各路明星爆出大瓜都对微博来说都是一次巨大的挑战,而技术就是在这种挑战中不断进步的。
人为错误
这部分其实总结一下就是–人是不可靠的。首先要承认人类这个感性、主观的物种的不可靠,然后才会想办法去规避这些不可靠带来的麻烦。这也正是我们在软件的生命周期中引入各种操作来避免这种不可靠的原因,包括设计文档、流程规范、代码审核、代码测试、技术运维……
总结
本文是《数据密集型应用系统设计》的第一篇读书笔记,主要是对全书的主角——“数据系统”——有个大概的认识。全篇比较偏科普性质,而且之前在组内有过相关分享,所以写起来比较顺手。以后也不知道能不能坚持写这本书的读书笔记,所以说不定是最后一篇呢,毕竟你永远也不知道自己能懒到什么程度。
参考资料
- 《数据密集型应用系统设计》
- Shopee 的分布式数据库实践之路



